Back from EC-TEL07
Another week, another conference :)
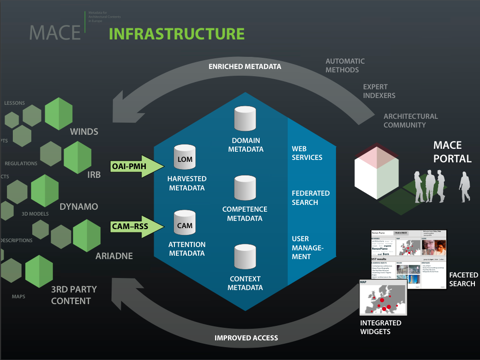
This time, it was the EC-TEL07 (European Conference on Technology Enhanced Learning) in Crete. Elisa Dalla Vecchia and I presented the MACE project (slides, video 1, video 2) and besides, met a lot of nice people.
The conference itself was really well organized. The keynotes (Hermann Maurer and Bruce Sterling) were excellent and big picture, covering a wide range of digital lifestyle topics and wild ideas. Digital quacks & charlatans, why Google is not so non-evil after all, telepathy is trivial, flying cars. No kidding. Many of the session talks, on the other hand, were not that exciting at all. I have the feeling many people in this area first build a “framework for…” before actually trying out some ideas on real learners.
More info on the conference blog, wiki and the flickr stream.
Greetings to Martin Memmel from DFKI, who I met to talk about the ALOE project and Christian Glahn, who presented nice work on Smart Indicators for learner feedback, and Joris Klerkx, who is quite into information visualization. I am looking forward to future developments, guys!
And just for the record, here are my favorite insider nerd joke conference memes:
- Magic doesn’t scale.
- Minigolf? Ouzome!
- “Everything is a platform” – freaky!
- Telepathy is trivial.
- “Anyways – back to me”
Freebase
I just came across freebase again, and I have to say this thing looks really prospering. Freebase is sort of a metadata / semantic web wiki, structured around topics, types and domains. Essentially, it lets users add descriptions of entities, such as movies, persons, buildings and relate them to each other. The set of properties used, of course, depends on the type of an entity. The project reuses a lot of Wikipedia or other free information, but the interesting thing is the structured approach and, for developers, especially the really powerful API with a very interesting query language approach based on JSON. Mashup time! :)
To get started, browse freebase, e.g. about, say, architecture!
Visualization and Aesthetics Research
Just a quick pointer to three interesting papers about the trends in and models of information visualization:
Andrea Lau and Andrew Vande Moere
Towards a Model of Information Aesthetics in Information Visualization
This paper proposes a model of information aesthetics in the context of information visualization. It addresses the need to acknowledge a recently emerging number of visualization projects that combine information visualization techniques with principles of creative design. The proposed model contributes to a better understanding of information aesthetics as a potentially independent research field within visualization that specifically focuses on the experience of aesthetics, dataset interpretation and interaction. The proposed model is based on analysing existing visualization techniques by their interpretative intent and data mapping inspiration. It reveals information aesthetics as the conceptual link between information visualization and visualization art, and includes the fields of social and ambient visualization. This model is unique in its focus on aesthetics as the artistic influence on the technical implementation and intended purpose of a visualization technique, rather than subjective aesthetic judgments of the visualization outcome. This research provides a framework for understanding aesthetics in visualization, and allows for new design guidelines and reviewing criteria.
While I find the triangle model based on Data, Interaction and Aesthetics quite enlightening and useful, I am not so convinced of the data focus and mapping focus classification. Anyways a great paper.
Robert Kosara
Visualization Criticism – The Missing Link Between Information Visualization and Art
Interesting points, especially the claim that we need to think about frameworks to criticize information visualization examples and techniques from different perspectives. The presented model, however, is quite simplistic, focussing on readability and recognizability, and based on that, a one–dimensional and —from my perspective—too shallow distinction of pragmatic vs. artistic approaches.
Fernanda B. Viégas and Martin Wattenberg
Artistic Data Visualization: Beyond Visual Analytics
A nice overview of not strictly analytic approaches to information visualization.
Forrester Research: Social Technographics
Just got my hands on the quite fascinating “Social Technographics” study from Forrester Research. They take a close look at the social and demographic structure of the social web population — unlike Technorati’s statistics which mostly focus on raw blog growth numbers and structural features of the blogosphere. The study is based on two surveys including including close to 5000 North-American individuals each.
Interesting facts:
22% of adults now read blogs at least monthly, and 19% are members of a social networking site. Even more amazingly, almost one–third of all youth publish a blog at least weekly, and 41% of youth visit a social networking site daily.
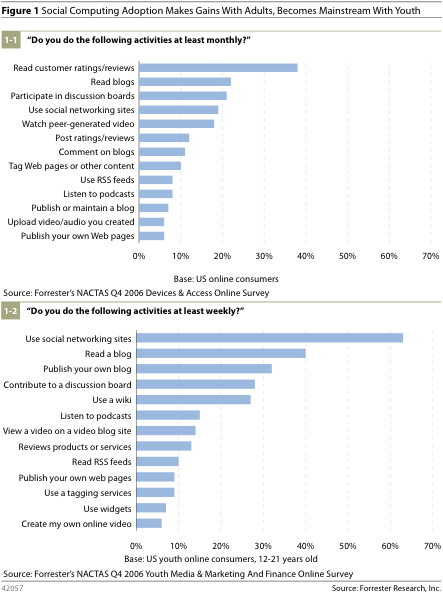
Based on an analysis of online participation and consumption practices, the authors identify six segments of users, ordered by degree of participation:
Innovationsforum Interaktionsdesign: a late review

Although finished already over a week ago, some words on the Innovationsforum Interaktionsdesign organized by the Interface Design Program at FH Potsdam (where I happen to study). To put it short: It was a blast!
Especially remarkable:
• The design concept of the conference itself: excellently conceived and executed with love to detail. See monomo for some pictures. Props and respect to formdusche
• The line-up was really impressive – find complete coverage of the talks at wmmna. Lots of pictures also on flickr, especially James King’s scribbled coverage of some of the talks — here’s the one of the 10 minute talk I gave together with Fabian at the student’s panel:

• Bruce Sterling’s talk was, as expected, “something completely different” and he really hit the nail on the head a couple of times:
Never thinking about it again is the ideal relationship of a normal human being and an object. That is the opposite of how designers think. I realized this when I was teaching at Art Center College of Design. My students were doing media design, some of them, and very commonly they would come out with some gizmo on a neck pendant. “See, the user wears this large device dangling around his neck, and…”
“No,” I would tell them, “your design project is not hung around the user’s neck. The user has other uses for his neck. This project is hung around YOUR neck. You’re the designer, you’re the one who has to obsess about the device, not them.” You obsess MORE. Let them obsess LESS.
Read Shaping Things if you haven’t yet.
Other than that, Anthony Dunne, Bernard Kerr and Tim Edler really impressed me.
An inspiring event, I wish we could have that every year!
Quantitative data visualization
Recently, a number of interesting online tools for quantitative data visualization popped up:
swivel.com
“…is a place where curious people explore all kinds of data.” (tag line)
It allows anybody to upload, visualize and share data sets. The diagrams can be embedded in any web page by using HTML snippets. I haven’t figured out yet if these update automatically, when the data set changes. If so, this is a really neat way to display dynamic graphs on your page. And the whole sharing/discussing data aspect is really interesting.

reinvigorate.net
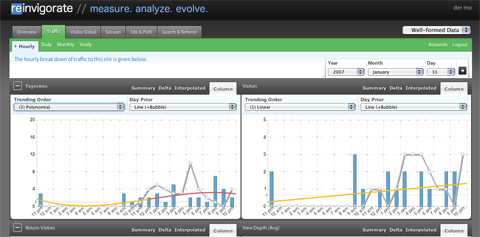
My favorite online web site analytics tool, which I totally forgot about, because it has been offline for two years or so. But the relaunch was really worth the wait, nice style, except for the glossy buttons (WHY?), the colors and visual ideas are really good. Also feature-wise, it easily puts google analytics behind – trend analysis with polynomial fitting, real-time analysis, in-depth stats etc. I recommend testing it out if you are a stats junkie as I am.
IBM: many eyes


Looks a lot like swivel, except there are far more visualization options and the diagrams are interactive (Java though – hrrr). Haven’t looked at it in depth yet, but it looks very interesting as well.
Husserl and tagging
A very nice paper on the “laissez-faire librarianship” often associated with tagging vs. more structured semantic web approaches. Most notable is that the discussion is put in the context of Husserl’s theory of reflections, intentionality and intersubjectivity.
D. Grant Campbell
Faculty of Information and Media Studies
University of Western Ontario
London, Ontario N6A 5B7, Canada
Abstract
This paper uses Husserl’s theory of phenomenology to provide a model for the relationship
between user-centered tagging systems, such as del.icio.us, and the more highly structured
systems of the Semantic Web. Using three aspects of phenomenological theory—the movement
of the mind out towards an entity and then back in an act of reflection, multiplicities within unity,
and the sharing of intentionalities within a community—the discussion suggests that both tagging
systems and the Semantic Web foster an intersubjective domain for the sharing and use of
information resources. The Semantic Web, however, resembles traditional library systems, in
that it relies for this intersubjective domain on the conscious implementation of domain-centered
standards which are then encoded for machine processing, while tagging systems work on
implied principles of emergence.
Papers on tagging
I am currently organizing my literature on tagging. When I started with research on that topic about a year ago, you could count the number of substantial contributions on one hand. Over the current year, however, the number of papers on this topic has sky-rocketed, which makes the whole area hard to oversee at the moment.
I will start with an overview of my subjective must-reads for now (all linked to citeulike):
Social tools for academic papers
When working with academic papers, you encounter the same old problems everybody has with digital data organization: categorize by author, date, topic, method or journal? Additionally, you have to keep track of the references for citation.
So I decided to try out one of the new public bookmarking tools for academic research: citeulike and connotea.
Book Review: The Long Tail
The Long Tail: Why the Future of Business Is Selling Less of More

Author: Chris Anderson
Year: 2006
Publisher: Hyperion
ISBN: 1401302378
Maybe the most fascinating read I had this year. Chris Anderson comes up with a very conclusive model how web commerce and communication differ from their “real-world” counterparts and what effects that has. Essentially, he shows that the common “80-20” rule (that most of the money/attention is spend on a few blockbusters) is not valid anymore in the web world. Rather, successful online shops make most of their money with niche products, each sold very seldomly. But there is literally millions of them — together with the cheapness of storage and distribution, outsiders are suddenly profitable. The same trend can be observed in the blogosphere, where individuals publish information independent of large media corporations.
This book had huge impact, in fact the long tail diagram has become an icon of the whole bottom-up, grassroots, amateurs vs. pros, wisdom of the crowds trend we experienced over the last years.
For my work, the whole development has high relevance: If everybody is hunting the cool stuff besides the mainstream, puzzling together his personal taste mostly made up of widely unknown stuff, this requires different paradigms for browsing, storing and discovery. I think it will take another couple of years, until we understand, what the “social media” revolution is about — besides big typo and beta badges.