VIS 2014
I long, long resisted going to IEEE VIS, but this year, it’s about time. I’ll moderate a panel featuring top notch speakers: Tariq, Scott, Matteo, Greg and I will try to shed some light on what it’s like to work with and publish data in the NGO context, and how we can improve! This should be interesting. Check out the (simple) announcement video here:
The other thing I am really looking forward to, is the tutorial I’ll teach together with Dominikus Baur. We will look at all the practical aspects of producing successful web-based data visualizations — except the actual data vis code. So, we will discuss deeplinking, performance, shareability, help and explanations, fallbacks, mobile optimizations – all the stuff that makes great web applications really great, but which we all underestimate all the time.
Looking forward! Who else is going? Ping me!
PS: Maybe we should do a datastories listener meetup? Or something?
OECD Data Portal
A few notes on a new, big project I have been involved with: The OECD Data Portal is now in public beta. It is still a bit rough around the edges, but we are excited to see the full website in its entirety. The main design credit goes to Raureif, and the UI implementation has been done by 9elements. I have been responsible for the chart design and specifications, and general data visualization strategy.
Unlike many of my other projects, this project is less about spotting patterns in the data, or communicating insights, but starts one step earlier: How can we actually make large collections of data sets available, and how can we guide users to the datasets they are looking for?
OECD Regional Well-Being

OECD Regional Well-Being: A new site for the OECD, and once again with my great collaborator Dominikus Baur and some help from my friends over at Raureif.
The site presents an exciting new perspective on more than 300 regions worldwide. As we all know, conditions inside a country can differ quite drastically, so going beyond the country averages presents an important step in the Better Life Initiative.
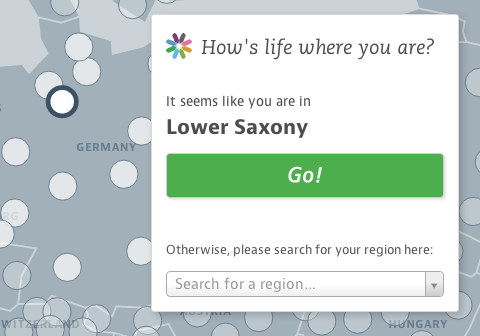
The user experience of the site is very consciously centered around the comparison of single regions in their context. Instead of presenting complex overviews, we start the experience with what people know best – their own home region. How does it compare to other regions in their country? And across all OECD regions? How have things developed over time?

The key visual element – the multi-colored star charts – represent the diversity of aspects we need to consider at when talking about regional differences. Each region receives a unique symbol, representing its particular well-being profile. This design principle was pioneered in the famous flower design of the OECD Better Life Index — which is part of the same initiative — and was now brought to a new logical extension for this new “family member”.

Reflecting your own region in context provides a natural starting point for further explorations. One particular option we offer is the “Regions with similar well-being” section, which suggests regions with similar indiator values all over the world. Who knew that Texas and Scotland are actually not that far apart, when it comes to well-being (well, except for the Safety aspect)? Or that Berlin has a similar profile as Alsace?
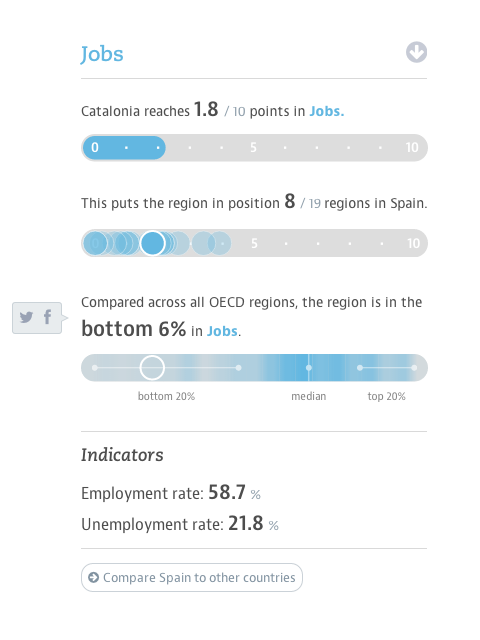
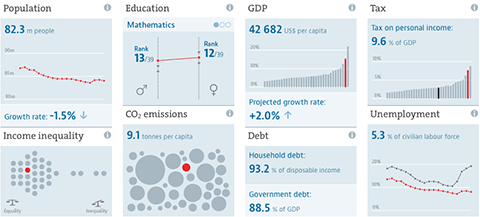
From a design point of view, the main challenge has been to deal with the complexity and scale of the data set. With ten indicators per region, most of which have also trend values, and 362 regions in the dataset, the site provides access to over 7000 data points. In designing the site, we made sure to introduce a hierarchy of information that presents the most important values values at a glance, but at the same always provides the context to a single data points that makes it meaningful, and reveals deeper information step by step.
Another detail we really like is that we added twitter and facebook buttons to all the auto-generated short factoid sentences, so you can easily spread facts you find interesting or surprising. Just hover with your mouse and wait for two seconds for the pop-ups to appear.
Here is a full region page in all its glory:

And finally — if you like the “no overview” approach, you should also definitely check out our datastories episode with Marian Dörk.
Now, go and find out how your region fares :)
PS: In case you would like to report on the project – why not use these crisp retina screenshots!
Data Cuisine: Barcelona

I am *ridiculously* excited to announce a new edition of data cuisine workshop. This time, it is the Data Cuisine Workshop Barcelona!
The workshop is happening in coordination with CCCB, the Big Bang Data exhibition, and Sónar. For the culinary side of the project, we will collaborate with Sebastian Velilla — a chef who has worked for the Alícia Foundation and is currently involved in the activities of the Torribera Food and Nutrition Campus of the University of Barcelona. And — it’s all happening in two and a half weeks (June 10-13). This. is. Crazy!
In case you are interested – register right now! (I expect things to move very fast, so be quick!)
Better Life Index: 2014 update
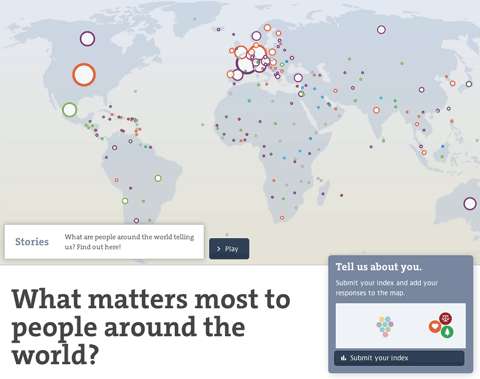
The OECD Better Life Index is one of the more popular projects in my portfolio, and now, entering its fourth year, it is still going strong, and is actively developed further. After adding gender and social inequalities, refining the sharing functionality and transitioning over from Flash to HTML5 in the years before, this year’s update is especially interesting: We are closing the loop by visualizing the responses from people all over the world using the site and sharing their Better Life Index with others.
Thanks again to my incomparable and invaluable collaborators Dominikus Baur as well as Timm Kekeritz and Frank Rausch from Raureif without whom none of this would have been possible.
Here’s a few of the new features and details:

The map initially shows the number of responses per country and gives a hint at the most favored topic per country. You can also switch to equal dot sizes, which highlights the favorite topic distribution across the world, which I found a quite interesting angle on the data.

Zooming in on a country, you can learn about the gender and age distributions, and the topic ranking per country (based on the indexes submitted). You can even compare to other countries or the average response.
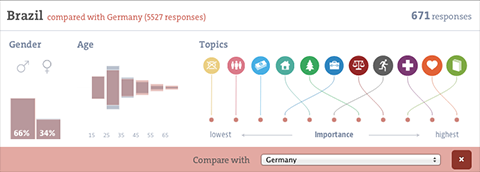
I had fun developing the force directed bubble behavior for the ranking visualizations, it is also used for the miniature visualizations of the submitted indexes and we plan to make it a core component of the Better Life Index toolbox. I would like to say thanks to Gregor for the original inspiration!
Also, on the details front — note how gracefully the visualization deals with identical values — they are all stacked neatly on top of each other, as they should have the same position in the ranking.

Last, there is a soft editorial touch with a “guided tour” through some of the most interesting facts to discover in the visualization, taking you for a quick tour around the world. I hear storytelling with big data is the next big thing, so we just wanted to hop on the bandwagon there :D. On a more serious note, these quick highlights can be an excellent way into a complex visualization and I will definitely explore these types of narrative techniques further in the future.

Anyways, I am really happy how the update turned out, and am especially looking forward to a whole new, but related site for the OECD we are launching soon! Stay tuned!
Mapping soccer fans
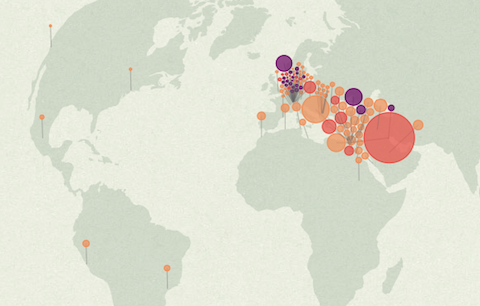
A quick note for a fun project I did together with David Bauer from the Swiss newspaper Tageswoche: “Zürich, Kairo, Bagdad: Wo auf der Welt eine Million FCB-Fans leben” — an interactive map of all the facebook fans of the soccer club FC Basel. While Basel and surroundings have the most fans per inhabitant, the highest absolute number of fans is actually located in Egypt – who knew?
The map features a little stepper that allows you to zoom out from Basel to the whole world in a few annotated steps. The map projection is azimuthal equidistant, so all points on the map have the correct distance and angle from the perspective of the center point — Basel.
It was fun to collaborate on this project. Thanks also to Herr Stucki for the help with the GEOJson!
Workshoppin’
Hey all,
I’ll give a (German language) workshop on data visualization together with Dominikus Baur in Munich on May 16 and 17.
The workshop is split in two days, with day one discussing the concept and design aspects of data visualization, while day two goes into the nitty gritty of building a data-based graphic from scratch.

I teach only occasionally, so this is a rare opportunity. I can only recommend to register as soon as possible :)
Also, a good opportunity to talk a bit about the last workshop Dominikus and I gave at resonate. It was a great group, and I was really impressed what the participants came up with in very short time. We worked with a dataset about movies and TV series from IMDb and after a day of basic introduction, the participants went from initial questions and concept over data explorations to visual refinement and annotation in what was basically a day of workshop time.



Tableau and RAW proved to be extremely valuable tools. It is amazing what you can achieve in really short time with these applications. The workshop was a big success, and a really nice experience, which also showed in the evaluation results.
Anyways, do consider signing up for the Munich event! And of course, please feel free to ask any questiony by email.
Upcoming appearances
Hey all,
it’s been busy times over here, with a lot of new stuff coming out in May, and also a few new opportunities to see me:
There’s a public Google Hangout with me on Wednesday April 30 organized by the CHI Belgium community. I’ll talk about unusual forms of data visualization – sculptures, food, etc. I think, it will be fun!
Next up: a panel at re:publica on May 06, with Jan Arpe, Maya Ganesh and Tariq Khokhar, on data visualization in a globalized world. I will show the new OECD Regional Well-Being website I have been working on together with Dominikus Baur over the last few months.
And, then there’s a workshop in Munich! Which deserves a post of its own :)
And, then there’s Oslo in June, and Basel in July – let me know in case you want to meet up.
Malofiej award
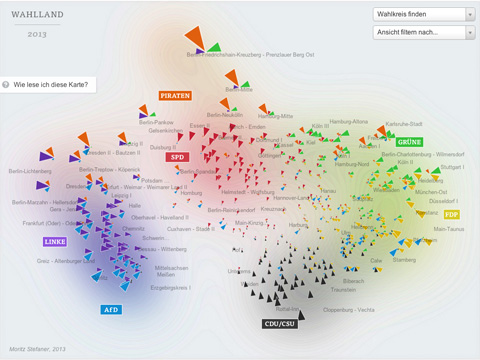
I am honored and proud to have received one of the prestigious Malofiej awards — sometimes called the Oscars of Information Design — for the Electionland/Wahlland visualization for ZEIT online.
Selfiecity

The selfiecity project has launched earlier this week, and boy, it has hit a nerve. We had 10’000s of visitors in the first few days, and hundreds of articles and posts linking to the project.