Emerging topics
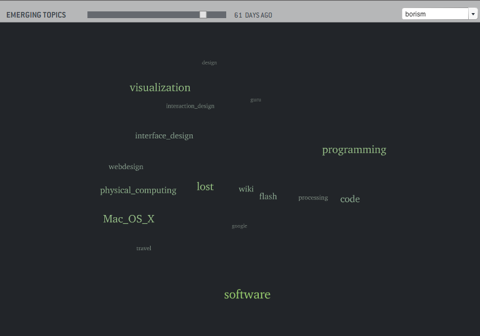
You might have seen the tag clouds posted below. I calculate tag positions based on co-occurrence, such that tags used together are placed closer to each other. Additionally, tags are scaled áccording to frequency.
A general problem I have with the resulting representation (and common tag clouds as well) is the fact, that every tag occurrence is weighted equally. As a result, these tag clouds never represent the current state of interest, but a very sluggishly changing summary of your archive. However, your interests and the corresponding vocabulary keeps moving on.
So I am currently investigating trends in tag clouds and how groups of related tags emerge and disappear again.
A first glimpse into the dynamical nature of tag structures.
December 11th, 2006 at 2:11 pm
hi, anscheinend hab ich zu viele tags oder ähnliches. wenn ich meine animation ansehen will, bekomme ich immer die meldung vom flash-player, dass ein skript den rechner verlangsamt. also halt ein typisches zeichen für entweder zuviele daten oder eine endlosschleife.
December 13th, 2006 at 4:43 pm
Thanks for the note, I have the same problem and will fix it soon. Most probably you just tagged too much :)
January 22nd, 2007 at 10:50 pm
[…] To see how that freshness measure changes over time, there is an animated version as well described in an earlier post. […]
February 19th, 2007 at 12:55 am
[…] am currently working on trends in individual tagging behaviour. You might have seen a first, animated version of my studies based on tag maps. The original animation shows the emergence of previously rarely used tags over […]