Emerging topics
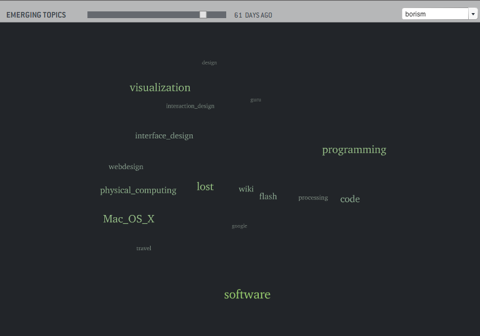
You might have seen the tag clouds posted below. I calculate tag positions based on co-occurrence, such that tags used together are placed closer to each other. Additionally, tags are scaled áccording to frequency.
A general problem I have with the resulting representation (and common tag clouds as well) is the fact, that every tag occurrence is weighted equally. As a result, these tag clouds never represent the current state of interest, but a very sluggishly changing summary of your archive. However, your interests and the corresponding vocabulary keeps moving on.
So I am currently investigating trends in tag clouds and how groups of related tags emerge and disappear again.
A first glimpse into the dynamical nature of tag structures.
Papers on tagging
I am currently organizing my literature on tagging. When I started with research on that topic about a year ago, you could count the number of substantial contributions on one hand. Over the current year, however, the number of papers on this topic has sky-rocketed, which makes the whole area hard to oversee at the moment.
I will start with an overview of my subjective must-reads for now (all linked to citeulike):
Social tools for academic papers
When working with academic papers, you encounter the same old problems everybody has with digital data organization: categorize by author, date, topic, method or journal? Additionally, you have to keep track of the references for citation.
So I decided to try out one of the new public bookmarking tools for academic research: citeulike and connotea.
MACE project
The MACE project website is online as a first version:
The MACE project sets out to transform the ways of e-learning about architecture in Europe. It will integrate vast amounts of content from diverse repositories created in several large previous projects as well as from existing architectural design communities.
MACE will provide a framework for community based services such as finding, acquiring, using and discussing about e-learning contents that were previously reachable only to small user groups. […] The project will develop and use several types of metadata for tagging contents: traditional content metadata and ontologies, context metadata, competence metadata and learning process metadata, usage related metadata and metadata acquired through social interaction, e.g. recommendations by peer users or blog entries.
I am engaged on the project as a part-time researcher here at FHP. A terrific chance to get some really good interfaces going, especially since there is a lot of data, even more metadata and a powerful consortium involved. I am looking forward to it!
Tag clouds

Just a little pointer to an ongoing project:
[edit: >> The latest version can be found here <<]
I am currently working on similarity (correlation-based) navigation mechanisms for tags and other nominal metadata and a trend measure (kind of hinted at in the interactive version with the green colors). I will soon post an update and a few explanations.
Tag Clouds 5.0 (German documentation at incom.org)
I would be happy if you could contribute your del.icio.us, ma.gnolia or furl tags, if you use one of these public bookmarking services. In this case, just do the following; it’s a one minute thing:
1. Go to https://api.del.icio.us/v1/posts/all?
2. The browser will ask you for your delicious username and password.
3. As a response, you will get an XML file containing all your posts. The browser page might look blank, but if you take a look at the source code, you will see it’s an XML file.
4. Send me the file (copy paste source code into a text file or save directly) along with a short notice, if you want it published in future experiments (with your username or anonymized).
Visualizing gaps in time-based lists
As a side product of my work on web feed visualization, I made a small comparison of different ways to deal with temporal information in lists of microcontent, such as e.g. blog entries.
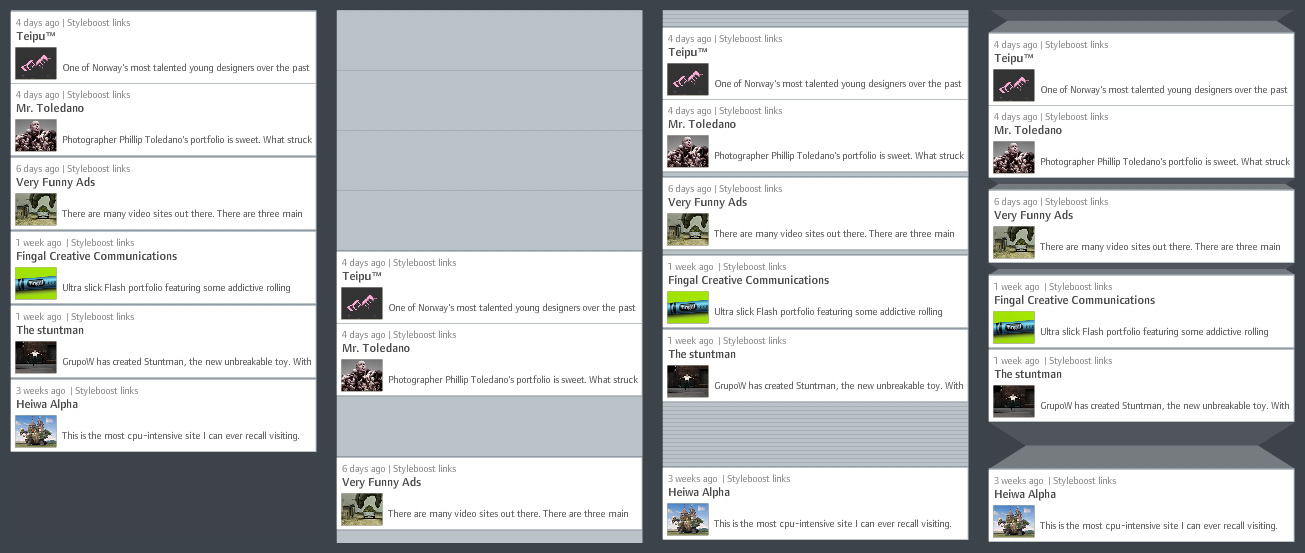
1) Ordered list without gaps: Clearly, the most space-efficient solution – however, only temporal ordering is preserved and not temporal structure. It is not visually evident how the items are distributed over time.
2) Calendar: Each time unit (days for example) has equal space assigned, regardless if there are items assigned or not. A precise display, however, very space-inefficient, since a lot of the display space is typically used for displaying “nothing”.
3) Accordion: Similar to calendar view, but empty time units are displayed on much less screen estate. This gives a pretty good first-glance impression of large gaps and close-together items. However, depending on the temporal structure, there might still be large streaks of wasted space for large gaps.
4) Folded gaps: This is the solution I propose (and which I believe is novel. If otherwise, I would be happy about a short notice!): Temporal gaps are displayed as if a part of the list was folded to the back of the display. Short gaps have almost the same size as in accordion view. Long gaps are larger, but do not grow linearly, but with the square root of the number of empty time units. Visually, this is justified by introducing shading to indicate that the “original material” is folded to the back. Folding also provides a plausible model for interactive adjustments such as regulating the gap size.
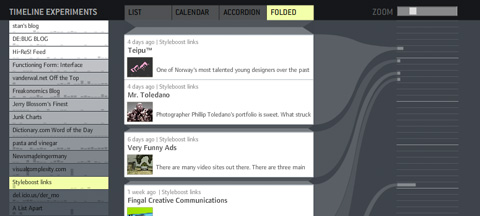
To support my argument, I also made small demonstrator based on actual web feed data. It takes a while to load (~700k of data), so please be patient. On the left, you have a menu for selecting different feeds. On the right, I drew a connection of each item to a calendar with fancy curved lines. You can adjust the size of the displayed items with the zoom slider.
Let me know if it works for you – technically and conceptually!
Microformats
I am a big fan of the Microformats initative. From the site:
Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards. Instead of throwing away what works today, microformats intend to solve simpler problems first by adapting to current behaviors and usage patterns (e.g. XHTML, blogging).
So essentially, the idea is: if you write a review (like I did below), announce an event, post a person or job profile — do it in a standardized way, so it can be reused and aggregated. The good thing is that there are lots of editors and readers already out there. So for example you can use the Tails Firefox Extension to automatically add events mentioned on web pages to your calendar or save address cards etc. Endless possibilities of seamless data interaction.
I use the Structured Blogging Plugin for WordPress to have ready-made forms for posting reviews. For the book review, I just entered the title and it grabbed all the meta-data from Amazon. Melikes!
Book Review: The Long Tail
The Long Tail: Why the Future of Business Is Selling Less of More

Author: Chris Anderson
Year: 2006
Publisher: Hyperion
ISBN: 1401302378
Maybe the most fascinating read I had this year. Chris Anderson comes up with a very conclusive model how web commerce and communication differ from their “real-world” counterparts and what effects that has. Essentially, he shows that the common “80-20” rule (that most of the money/attention is spend on a few blockbusters) is not valid anymore in the web world. Rather, successful online shops make most of their money with niche products, each sold very seldomly. But there is literally millions of them — together with the cheapness of storage and distribution, outsiders are suddenly profitable. The same trend can be observed in the blogosphere, where individuals publish information independent of large media corporations.
This book had huge impact, in fact the long tail diagram has become an icon of the whole bottom-up, grassroots, amateurs vs. pros, wisdom of the crowds trend we experienced over the last years.
For my work, the whole development has high relevance: If everybody is hunting the cool stuff besides the mainstream, puzzling together his personal taste mostly made up of widely unknown stuff, this requires different paradigms for browsing, storing and discovery. I think it will take another couple of years, until we understand, what the “social media” revolution is about — besides big typo and beta badges.
First post on this blog
Hereby I declare this blog as officially OPENED!
I am myself curious where it will lead me — my motivation is to share my thoughts, discoveries and experiments I will do while working on my Master’s thesis in Interface Design at FH Potsdam with you. But occasionally, I might also just post related information or reviews of things I discover. Sharing is caring!