Where the wild bees are
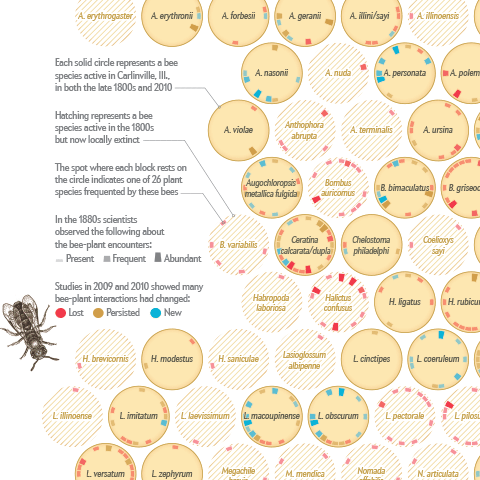
I am happy to announce that I just published my first information graphic for Scientific American on a topic that is very close to my heart – bees :)
Together with my passion for communicating complex science, Jen Christiansen correctly realized this package would be an offer I could hardly resist (despite my packed schedule), and I am really glad how the project and collaboration turned out.
Personally, I am always keen on hearing the inside stories behind projects — so,  here is me returning the favor, with a brief overview of how I approached the project:
Mapping Electionland
I created a whole new kind of election map for the German Bundestag elections 2013 for ZEIT Online. Instead of showing the electoral districts results on a geographic map, or in a table, I decided use the data to map a new land: Electionland (german version | english version), where all the districts which vote in a similar way are located nearby. This new kind of map allows us to see a Germany grouped by lifestyles, preferences and attitudes.
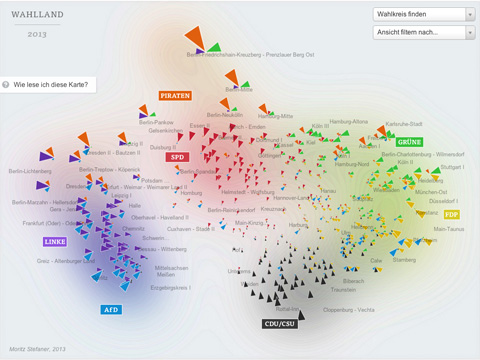
Here is some background on how I created this map. First of all, I need to normalize the data and make the parties comparable. To this end, I applied a z-score normalization on the data. In short, a z-score centers the data (so the average value is at zero), and it rescales the data, so that one standard deviation difference from the average lands at one, two standard deviation differences from the average lands at 2, etc. This makes the relative differences in voting behavior comparable, even if we compare huge parties with smaller ones.
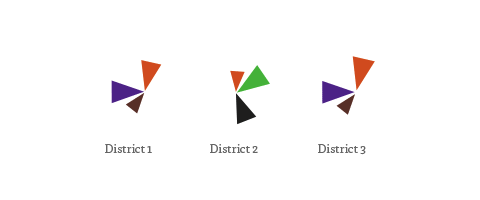
In the map, the triangle sizes correspond to these z-scores per party; I only show the results above average – these are the “characteristic” parties for a district. Each color and angle stands for one party.
I then use scikit-learn to calculate a 2-dimensional map of the resulting “electoral district space” using Multi-Dimensional Scaling or short: MDS.
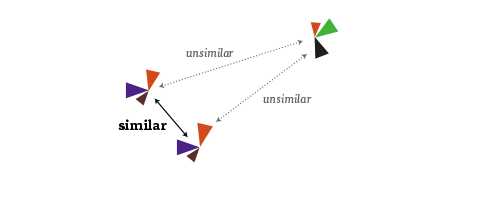
It is an algorithm that you can feed a matrix of similarities between objects (in our case, how similarly the districts voted), and it will attempt to find an arrangement that expresses these similarities as good as possible on a two-dimensional map. (For me, also a nice flashback to my 2005 B.Sc. Thesis, where I investigated MDS and related algorithms quite a bit :)
Some words about the interpretation of the map: First of all, it is important to note that the rotation of the map is a purely aesthetic choice. The MDS algorithms defines only a relative space, where the positions of all elements with respect to each are important, but not on absolute axes. But within the data, some interesting axes seem to emerge nevertheless: top-to-bottom seems to be correspond quite well to the traditional left-to-right spectrum. The left-to-right axis to interpret is a bit trickier but definitely seems related to social status or income. Also interesting to see how the blue AfD party — a newly founded euro-sceptic protest party, sort of a wild card — seems to be all over the map in the vertical center. A bit shocking also to see how there still seems to be a gap in Germany (the island on the left in pretty much exclusively ex-east Germany), with only Leipzig and Postdam (yay) bridging the gap. A note on the huge orange triangles for the Pirate party – actually, their results were not that great, but the enabled them to be very much above average in some districts.
A few words on workflow: For the frontend, I used my new favorite development combo of d3, coffeescript and SASS. In addition, I used the jQuery plugins select2 for the dropdowns and qTip2 for the tooltips.
The labels of the parties and the districts were actually hand-arranged in Adobe Illustrator. I first exported a rough version of the graphic generated with d3 using the very handy SVG crowbar bookmarklet. I hand then hand-tweaked the placements in Illustrator, and saved the resulting graphic as an SVG, which I then dynamically load into page using a combination of this technique with this one (to make it IE9 compatible). Because the layer names actually translate to group IDs in SVG, I was also able to identify the graphics elements from d3, and assign them individual click actions, etc. A very promising approach which I will surely explore further in the future.
You might wonder how I achieved the blurry contour line look in the background – the answer is simply (and a bit embarassingly) Photoshop :) Again, I used a rough version of the graphic, which was then blurred, levelled and edge-detected.
And, yes, it would definitely be interesting to compare 2009 and 2013, and see which districts moved around how much :) but this is tricky due to both the districts structure as well as the parties for vote not being exactly the same. Happy to share my data though, in case anyone is interested in that type of analysis :)
Look ma, no flash!

We reworked the OECD Better Life index. Besides a general facelift and interface overhaul (top work by Raureif, as usual), more languages (Spanish and Russian), the biggest change has been to replace the Flash-based interactive visualization with an HTML5 based component. Big congratulations to Dominikus Baur for the feat of accomplishing something very close to the Flash original (and in some parts even better)!
Dominikus has a super-useful in depth write-up of all the many little tricks that went into optimizing the graphics over on his blog, so I’ll shut up now and let the dirty rectangles do the talking.
Keynote at European Communication Summit
My speech from the summit. No big surprises for long-time followers, but a good summary overall, I guess. Also, I wear a suit!
Stadtbilder — mapping the digital shape of cities
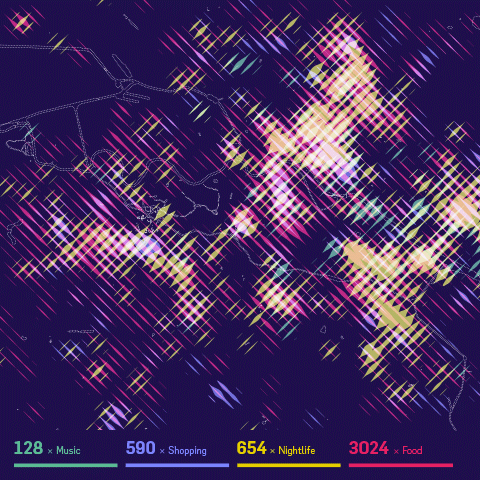
Stadtbilder (“city images”) is a new little side project of mine — an attempt to map the digital shape of cities. I am increasingly fascinated by the idea of mapping the “real world” — life and culture as opposed to just physical infrastructure — and when I learned about the really deep datasets Georgi from Uberblic had been collecting, I just had to work with the data.
The maps show an overlay of all the digitally marked “hotspots” in a city, such as restaurant, hotels, clubs, etc. collected from different service like yelp, or foursquare. What they don’t show are the streets, the railroads, the buildings. I wanted to to portray the living parts of the cities as opposed to the technical/physical infrastructure you usually see on maps.The only exception are the rivers and lakes, because I felt they help a lot in orienting on these fairly abstract maps.
While the designs are meant to be printed, as a digital companion, the website helps you decipher the posters by providing a little map overlay on click. If you are interested in a print, please sign up to be notified when prints are available — I still need to figure out the precise logistics. (Let me know if you know of a high-quality poster printing and shipping service a la imagekind which can also ship from EU/worldwide..)
For now I settled on the three main German cities, because they have very different characteristics, and I know them very well. But I might be convinced to do other city editions as well :)
Here are some process shots!
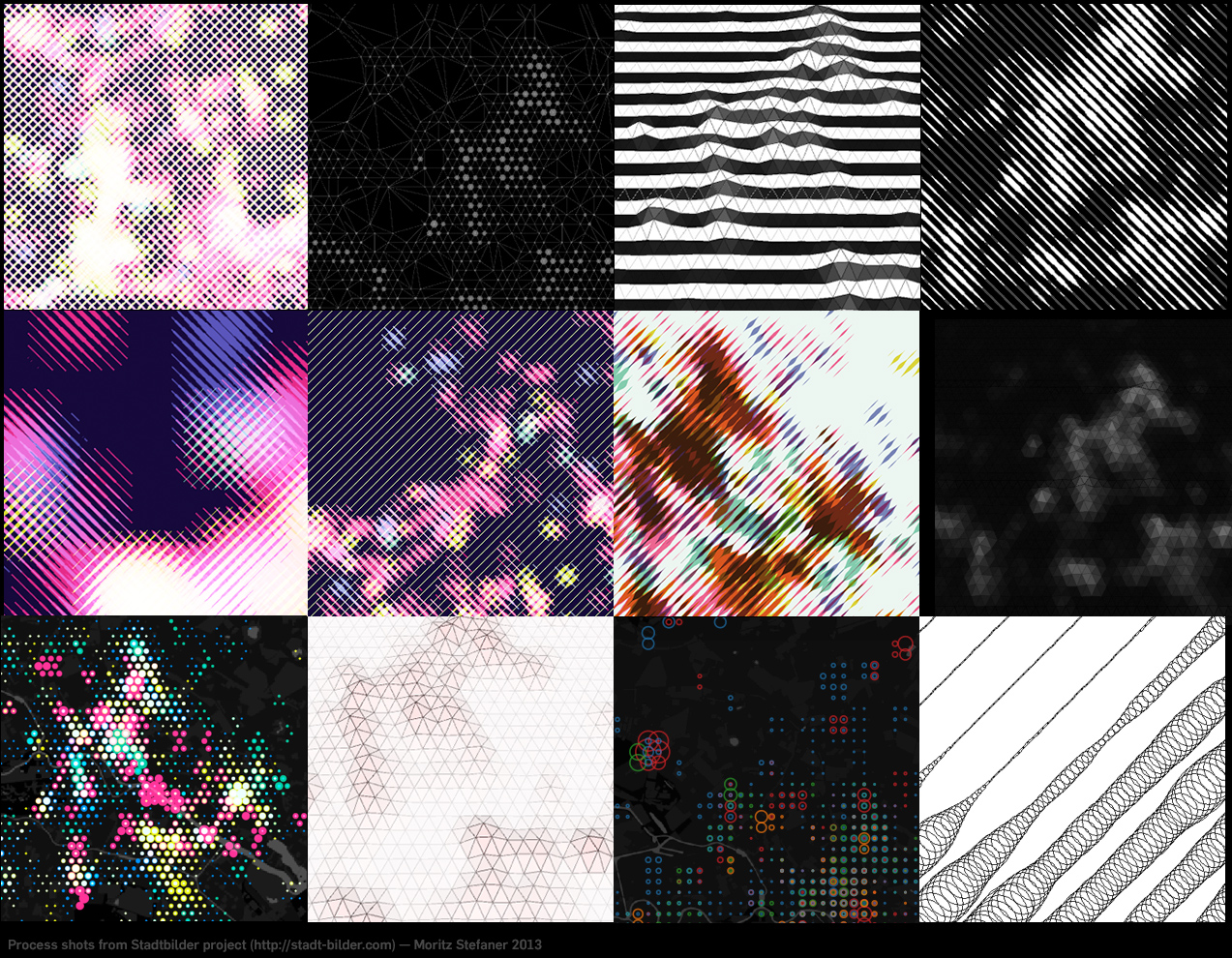
It took me a while to figure out how to overlay these four different heatmaps on top of each other. I experimented with 3D manifolds, different dot patterns, small multiples, etc. etc. In the end, I am really happy with the solution I came up with, as combining always two of them in one stroke direction allows to decipher all of the dimensions, and just by looking at stroke width and brightness (if the two overlap), no need to do “color mixing reverse engineering” in your head, which is pretty much impossible anyways. The downside of this approach is obviously a low spatial resolution.
How does it work technically?
I first query the Uberblic API (not public yet, sorry ;) for the scores in the different categories by marching through a hexagonal grid.
From the values, I first draw fairly blurry heatmaps in processing:

I then walk over these heatmaps pixel by pixel in diagonal lines, and draw on a new canvas a line whose stroke corresponds to the brightness of the pixel on each step:

and then I merge and simplify these images in Illustrator. That’s it!
In other news, the Berlin version made it to the cover of WEAVE magazine already (but it should be noted that for this use case, the background was tweaked more into a blueberry tone, the original is way more violet):

If you find this project interesting, Flowingcity hosts a collection many more projects in this direction.
Anyways, let me know what you think of it!
Update: Prints are now available!
Interview for Nathan Yau’s new book “Data Points”

Nathan Yau‘s new book “Data Points” is out, and while I am still waiting for a copy, here is already a short contribution I made – a few paragraphs of bla:
Nathan Yau: With client work, you must hear “innovative”, “compelling”, and
“engaging” often. Personally, I get a lot of this, and potential clients often don’t have data to work with. What makes a project interesting to you and worth your time?
Moritz Stefaner: In hindsight, the most satisfying projects for me were the ones, where the client or project partners were able to follow me in exploring, questioning, and extending the original data basis and project, sometimes going far away from the original project idea. Some ideas sound really good in the beginning, but turn out bland or much too complicated once executed with real data. Other ideas sound boring beforehand, but become exciting in a specific context. And other ideas you just develop by getting inspired from the data material itself. So, I realize this approach is a lot about trust and also flexibility on side of the client, but is the only way to get your visualization on point, ultimately.
NY: For people like us, the data is interesting as a CSV file, but most
don’t get that luxury. What role does aesthetics play in making data
interesting to a wider audience? What about truth? (You are after all,
the truth and beauty operator :).
MS: I honestly hope, and sometimes think, that the playfulness and organic nature of some of my visualizations does actually get people excited about a topic they would not have been interested in beforehand. I do like to dig in data and be a little “data detective” myself, and if my work can contribute to getting more people excited about querying and questioning data, and, most importantly, come up with new questions to ask, than I am happy :) Aesthetics and appeal are of course a big part of the equation here, besides, of course, relevance of the information presented and truthfulness of the representation. But to me, aesthetics is very little about “decoration” – in my world, a clearly pronounced, rigorous, characteristic, “on point” representation of data lets the inner beauty of a compelling data set shine, instead of trying to “sex up” bland lists of facts.
NY: When getting started with visualization, everyone seems to want to know
the “rules” of turning data into geometry. Are there any rules?
MS: There are no hard rules, but, as in any skill-based profession, there are some things that work better than others, and as for any cultural activity, you are not acting in the void, but in an established set of conventions, expectations and common knowledge. In my experience, great works are not strictly adhering to “the rules”, but, at the same time, are very sensitive to these two types of contexts, and are able to refer to, and sometimes even play with them.
NY: What’s the first thing you do when you have your data and get started on
a project?
MS: Get a coffee, put on a DJ set, fire up Tableau and or Gephi, and Sublime Text for Python and data massaging and plot the sh*t out of the data. Then inspect, take a day to do something else, and follow up on the interesting perspectives. To continue, I might transform the existing data, get some new data, or take one of the interesting, but still very generic views and start to tailor it more to the specific issue at hand.
—
Looking forward to having a copy of the book in my hands! And thanks, Nathan!
—
Btw, a few weeks ago, iCharts interviewed me, too. Good times!
Gender balance visualization
So, I made this thing on how many women speakers we have on stage at the type of conferences I like to go to. Personally, I think our field is probably already quite grown-up in respect of diversity and balance, but I think we could still do much better. I hope my small data collection and visualization helps a bit for organizers to reflect where they would like to land on my x-axis :) Relatedly, if somebody has good intentions, but trouble finding good female speakers, drop me a line, I know plenty.
“Weltbilder” master course
This semester, I taught a master course on information visualization at HfK Bremen. It was quite fun and I think I was able improve a bit on the teaching side compared to the first full course I taught two years ago.
The topic was “Weltbilder” – “World views” which has become sort of a theme for my work lately. Here are the introductory slides and reference projects:
The course took place on 8 full days over the course of four weeks in February and March 2013. Overall, I had more than 20 students in the course (although some were only listening in without handing in a final project). The first few sessions were partly filled with me teaching basic craftmanship (slides—30MB) and establishing context, while the students gave presentations on some of my favorite scientific papers and articles (dropbox) and practitioners (such as Nathalie Miebach, Stefanie Posavec, Density Design, Santiago Ortiz, Nicholas Felton, Periscopic, Stamen, Ben Fry, Martin Wattenberg & Fernanda Viegas and the NYT graphics desk). We also had a few practical exercises on drawing family trees and fixing broken charts.
The second half of the course was much concerned with the student’s projects, and I did mostly 1:1 consultations. You can find a few of the final projects here. I like how the course results reflect the diversity of the students themselves – we had artists, computer scientists, journalists, people from humanities – quite a mixed bunch. Overall, I am quite happy with how things worked out and hope I could excite a few of my students to keep doing things in this field :)
Here are two of my favorite projects:
but in sum, they were all pretty nice in one way or the other :) Here’s the gallery
Look ma, no story!
Storytelling has been one of the big buzzwords in data visualization the last year. By now, there are even whole conferences about the topic and I heard even some podcasts carry the word in their name :D
So, one could be tempted to think that storytelling is the magical ingredient to turn boring charts into killer visuals, make the blind see and save the world at large.
But, as so often, the pure and simple truth is rarely pure and never simple.
In fact, some of my favorite visualizations have no story to them.

Look at the legendary map of the market. A fantastic tool to understand the state of the stock market at one glance.

Consider Aaron Koblin’s Flight Patterns.

The brilliant map of optimal tic-tac-toe moves by xkcd.
And so on.
Tools have no stories to them. Tools can reveal stories, help us tell stories, but they are neither the story itself nor the storyteller.
Portraits have no story to them either. Like a photo portrait of a person, a visualization portrait of a data set can allow you to capture many facets of a bigger whole, but there is not a single story there, either.
Let us not forget about these important genres. There is more to information visualization than punchlines.
—
Update: After a few twitter discussions, here is a clarification: I argue against the often heard claim “every good visualization tells a story”. I would agree that, in a loose reading of the word, you could say that some of the above visualizations “reveal stories” or might “trigger stories” in the viewer’s mind.
Resonet

Resonet is an attempt to map the twitter community around the resonate festival, using a technique similar to the vizosphere I made earlier. This time around, I used a zoomable SVG map, which makes text labels searchable. Make sure to also check out the data files and analysis, and feel free to remix the data!