Quantitative data visualization
Recently, a number of interesting online tools for quantitative data visualization popped up:
swivel.com
“…is a place where curious people explore all kinds of data.” (tag line)
It allows anybody to upload, visualize and share data sets. The diagrams can be embedded in any web page by using HTML snippets. I haven’t figured out yet if these update automatically, when the data set changes. If so, this is a really neat way to display dynamic graphs on your page. And the whole sharing/discussing data aspect is really interesting.

reinvigorate.net
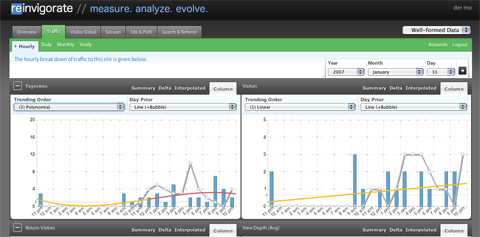
My favorite online web site analytics tool, which I totally forgot about, because it has been offline for two years or so. But the relaunch was really worth the wait, nice style, except for the glossy buttons (WHY?), the colors and visual ideas are really good. Also feature-wise, it easily puts google analytics behind – trend analysis with polynomial fitting, real-time analysis, in-depth stats etc. I recommend testing it out if you are a stats junkie as I am.
IBM: many eyes


Looks a lot like swivel, except there are far more visualization options and the diagrams are interactive (Java though – hrrr). Haven’t looked at it in depth yet, but it looks very interesting as well.
Husserl and tagging
A very nice paper on the “laissez-faire librarianship” often associated with tagging vs. more structured semantic web approaches. Most notable is that the discussion is put in the context of Husserl’s theory of reflections, intentionality and intersubjectivity.
D. Grant Campbell
Faculty of Information and Media Studies
University of Western Ontario
London, Ontario N6A 5B7, Canada
Abstract
This paper uses Husserl’s theory of phenomenology to provide a model for the relationship
between user-centered tagging systems, such as del.icio.us, and the more highly structured
systems of the Semantic Web. Using three aspects of phenomenological theory—the movement
of the mind out towards an entity and then back in an act of reflection, multiplicities within unity,
and the sharing of intentionalities within a community—the discussion suggests that both tagging
systems and the Semantic Web foster an intersubjective domain for the sharing and use of
information resources. The Semantic Web, however, resembles traditional library systems, in
that it relies for this intersubjective domain on the conscious implementation of domain-centered
standards which are then encoded for machine processing, while tagging systems work on
implied principles of emergence.
Tag maps update
As promised, here is an update to the tag maps application I introduced below along with some explanations.
For the impatient: HERE’S THE LINK
(Update again: *The latest version can be found here*)
And for the curious: Here’s the explanations: → read more
Personal network search
For my thesis, I am working on interfaces for the socio-semantic web. How can we exchange structured information snippets (“microcontent”) and metadata in small communication cliques via RSS – and what interfaces do we need for that?
One really hot perspective here is the search for information from a network of trusted sources, and this is exactly what the people at Stanley James’ company lijit do. They provide you with a personalized search engine, which returns google results only from
- – your own published information (via your blog, public bookmarking tools, flickr, photo sharing, etc.)
- – plus information published or marked as “good” from people you trust
So in a nutshell, you can search your own network (“What have people I know bookmarked or published about the new iPhone?”) or other people’s networks (“Stan is the expert on social networks – let’s see what he and his friends have bookmarked or published about it.”)
This is definitely quite stimulating. It still has to turn out in which situations a personal network search is far superior to the global web search or a personal, local search on my own resources and if people will adopt it. But I have the strong intuition that they are filling a huge gap here: connecting people and contents on web scale independent of individual bookmarking or publishing tools. This is kind of a meta-service for what comes after Web 2.0.
You can try searching my network here: